
Time traveling with data science: In this blog series, we will cover some of the different techniques that make up time series analysis. This first post will provide an overview of the different types of analysis possible and answer the question of what can be done with such tools. The interested reader can find more details in the authors` recently published article „A Systematic Review of Python Packages for Time Series Analysis„.
A time series is an ordered set of data points generated from successive measurements over time. For example, in the context of IoT, measurements from sensors typically comprise time series (e.g., physical values such as pressure, temperature, electrical voltage, etc.). This information can be used as a basis for analyzing the state of machines or workflows. Data scientists have a wide range of tools at their disposal to analyze time series. Some of these techniques are developed in different contexts (bioinformatics, neuroscience, signal processing, economics, etc.) and implemented in various libraries. As a consequence, it can be challenging to keep an eye on the big picture. For this reason, we decided to start our series of blog posts by giving an overview of different time series analysis tasks. This helps to first understand what can be done with time series analysis. The interested reader can also get more detailed insights into our work (Siebert et al. 2021), where we reviewed 40 open-source Python packages dedicated to time series data analysis.
More about data science: What does Paul Bocuse have to do with data science?
The literature of time series analysis – also called time series data mining – has defined several tasks (see, for instance, (Esling and Agon 2012)). Below, we provide a selective overview.
Indexing
One of the fundamental tasks is called Indexing (also called query by content). Indexing is the task of finding similar time series (or a given pattern or a subsequence of a time series) in a database. Searching for similar time series is the basis for other analysis tasks (such as clustering or motif discovery, for instance).
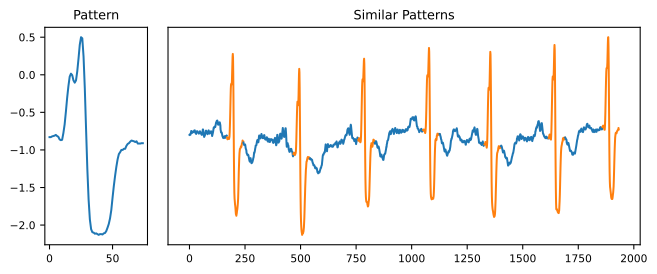
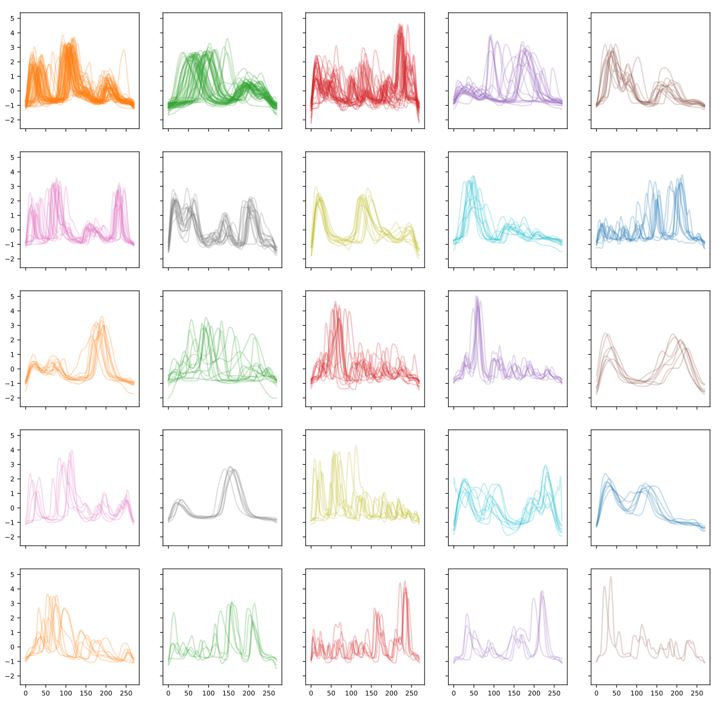
Clustering & Classification
Clustering is the task of grouping similar time series into clusters.
Classification is the task of assigning a predefined class to a time series.
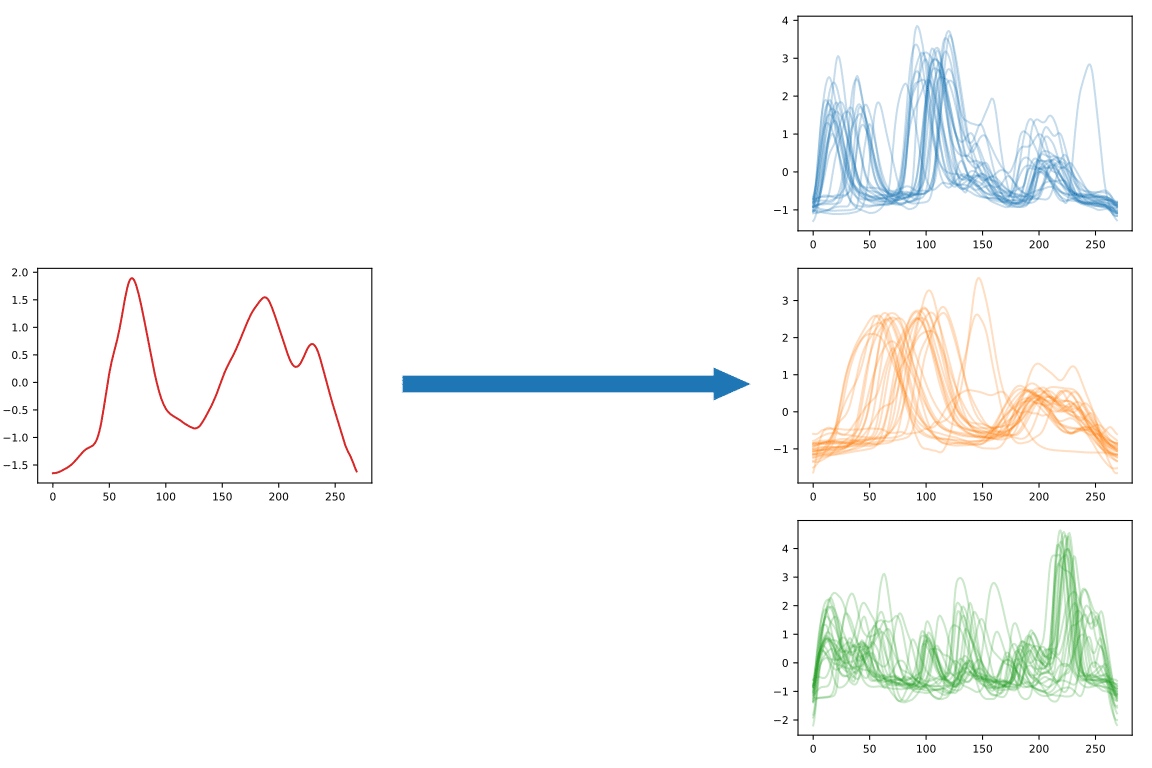
Both clustering and classification output groups of time series. In the case of classification, the groups are predefined (called classes or labels), while in the case of clustering, the groups must be found from the structure of the data, such as statistical characteristics.
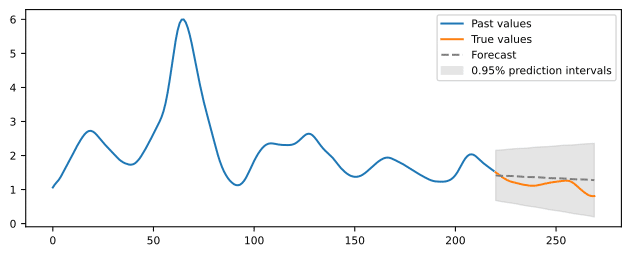
Forecasting
Forecasting (also called prediction) is the task of predicting future values of a time series given some past data. This is probably the best-known and most frequently used task, and there are many examples of forecasting applications. Sales, product price, or stock option prediction are typical examples from the field of finance.
Anomaly detection
Anomaly detection (also called outlier or novelty detection) is the task of finding abnormal data points (called outliers) or subsequences (called discords).
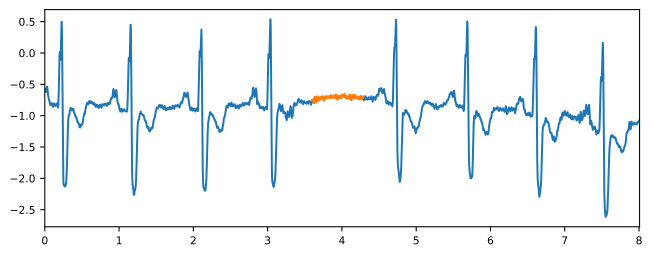
Change point detection
Change point detection is the task of finding points in time where the statistical properties of the time series (like mean, variance) change abruptly. Change point detection tests are often used in manufacturing for quality control.
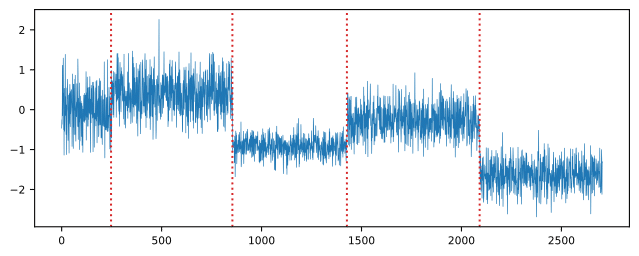
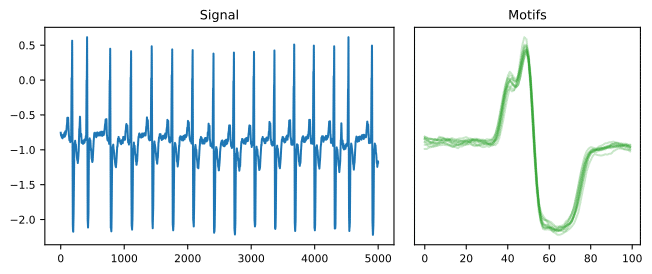
Motif discovery
Motif discovery is the task of finding time series subsequences that appear recurrently.
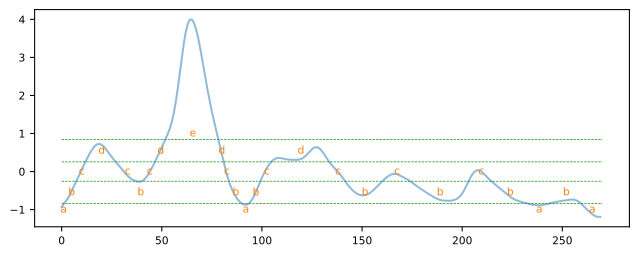
Segmentation
Segmentation (also called summarization) is the task of creating an accurate approximation of a time series by reducing its dimensionality while retaining its essential features.
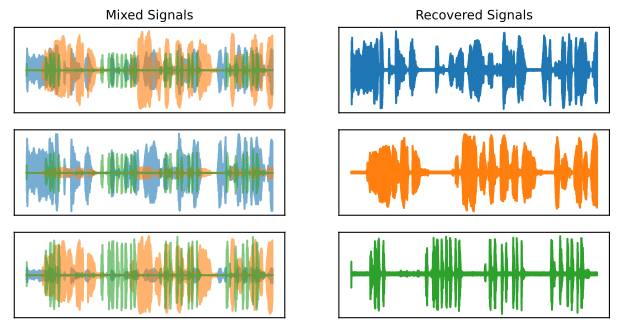
Blind source separation
Blind source separation is the task of recovering the source signals from a set of mixed signals. The challenge is to do this with very little information about the sources themselves or the mixing process. A typical example is to isolate the sound of different musical instruments playing together.
Time series analysis can be challenging both on a theoretical level and from an engineering standpoint. In our paper (Siebert et al. 2021), we provide a systematic survey of the currently maintained Python packages dedicated to this topic. In addition to providing an overview of the implemented tasks, we evaluated other practical aspects, such as the presence of datasets and metrics for evaluating the results, or the state of the documentation. Check out the article here and the interactive overview here.
Also check out the following blog articles:
- Time Traveling with Data Science: Focusing on Change Point Detection in Time Series Analysis (Part 2)
- Time traveling with Data Science: Outlier Detection (Part 3)
- Time Traveling with Data Science: Pattern Recognition, Motifs Discovery and the Matrix Profile (Part 4)
You are also interested in working on projects involving time series analysis? – Contact our expert Dr. Julien Siebert.
Publication bibliography
Esling, Philippe; Agon, Carlos (2012): Time-series data mining. In ACM Comput. Surv. 45 (1), pp. 1–34. DOI: 10.1145/2379776.2379788.
Siebert, Julien, Janek Groß, and Christof Schroth (2021): A Systematic Review of Packages for Time Series Analysis. In Engineering Proceedings 5, no. 1: 22. DOI: 10.3390/engproc2021005022

