
In diesem Blogbeitrag erklären KI-Expertinnen und Experten, welche Komponenten zu LLMs (Large Language Models, deutsch: große Sprachmodelle) gehören.
Die Funktionsweise eines LLMs: 4 Schritte bis zum Ergebnis
Große Sprachmodelle, wie wir sie heute kennen, sind nur die Spitze des Eisbergs. In der Geschichte der Künstlichen Intelligenz wurden Sprachmodelle – Modelle zur Lösung sprachbezogener Probleme (Übersetzung, Klassifikation, Textgenerierung) – mit Techniken entwickelt, die nicht immer auf neuronalen Netzen basierten (z.B. Hidden-Markov-Modelle). Heute erleben wir die Ära der Transformator-Modelle (das T in GPT): Neuronale-Netze-Modelle, die auf dem »Attention«-Mechanismus aufbauen.
Grundsätzlich kann ein Large Language Model (LLM) in vier Hauptteile oder Funktionen unterteilt werden:
- Tokenisierung (Tokenizer)
- Einbettung (Embedding)
- Berechnung der Wahrscheinlichkeit des nächsten Tokens (Vorhersage)
- Strategien zur Auswahl der Ausgabe (manchmal auch Dekodierung genannt).
Tokenisierung: Vom Text zum Token
Der erste Teil, die Tokenisierung, besteht darin, einen Text in kleinere Teile zu zerlegen. Für uns Menschen ist es am natürlichsten, Wörter als Token zu verwenden. Es gibt verschiedene Tokenisierungstechniken, von der Verwendung einzelner Zeichen über mehrere Zeichen (»n-grams«, Teilwörter) bis hin zu Wörtern. Die Wahl einer Tokenisierungstechnik ist eine Abwägung zwischen zwei maßgebenden Parametern. Zum einen wird die Gesamtzahl der möglichen Token berücksichtigt. Bei der Verwendung von Einzelzeichen in ASCII würden wir potenziell 128 Token erhalten. Bei der Verwendung von Wörtern im Englischen wären es etwa 200.000 Token. Im Deutschen wären es potenziell mehr. Zum anderen wird der semantische Informationsgehalt betrachtet. Einzelzeichen enthalten im Vergleich zu Wörtern nicht viele Informationen. Aktuelle LLMs haben auf Tokenisierungsverfahren umgestellt, die Teilworte benutzen. Beispiele hierfür sind Byte-Pair Encoding, Wordpiece, Unigram und Sentencepiece.

Embedding: Vom Token zum Vektor
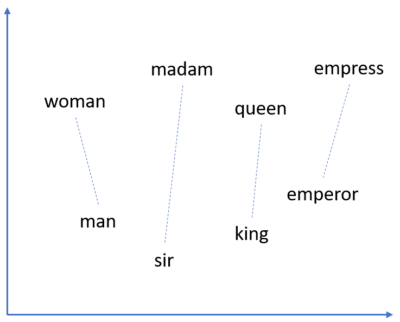
Der zweite Teil, die Einbettung (Embedding), besteht darin, Token auf Vektoren abzubilden. Obwohl die Forschung zu Worteinbettungen schon früher begann, ist eine der ersten bekannten Einbettungstechniken word2vec (2013). Dies ist ein Schlüsselelement, das es Analysetechniken (wie neuronalen Netzen) ermöglicht, mit Text zu arbeiten. Einbettungen werden in der Regel so berechnet, dass zwei semantisch ähnliche Token zu einem ähnlichen Vektor führen. Die Einbettungstechnik BPEmb wendet beispielsweise die Byte Pair Encoding Tokenization auf Wikipedia-Artikel in verschiedenen Sprachen an und verwendet GloVe, um Vektoren zu erzeugen, die semantische Informationen enthalten. In der Transformers-Architektur werden Token nicht nur aufgrund ihrer Semantik, sondern auch aufgrund ihrer Position im Satz in Vektoren eingebettet (so genanntes Positional Encoding).
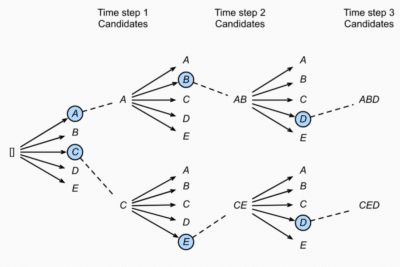
Der Kern des LLM: Vorhersage des nächsten Tokens
Der dritte Teil ist die Berechnung der Wahrscheinlichkeit des nächsten Tokens. Dies ist der Kern der LLMs und der Grund, warum sie so groß sind. Obwohl im Prinzip jede Vorhersagetechnik funktionieren würde (man könnte hier sogar Random Forest verwenden), verwenden alle aktuellen LLMs neuronale Netze und die meisten (bis heute) die Transformer-Architektur. Die Wahl der Architektur hängt in erster Linie von der Fähigkeit ab, lange Eingaben (den so genannten Kontext) zu erfassen, auf vielen Daten mit möglichst wenig Rechenaufwand zu trainieren und so gut wie möglich zu sein.
Dekodierung: von der Token-Wahrscheinlichkeit zum (hoffentlich lesbaren) Text
Sobald das Modell eine Wahrscheinlichkeit für alle möglichen Token berechnet hat, muss entschieden werden, welche Token als nächstes ausgegeben werden sollen. Die Dekodierungsstrategie kann einfach sein (z. B. Greedy Search: immer das wahrscheinlichste Token auswählen oder Top-K Sampling: aus den k wahrscheinlichsten Token auswählen) oder komplexer (z.B. Beam Search: aus den wahrscheinlichsten Token-Sequenzen auswählen oder Contrastive Search: die Wahrscheinlichkeit des Tokens gegen seine Ähnlichkeit mit dem Kontext abwägen).
Training mit ausreichend Daten und Feinabstimmung
Heutige LLMs werden zunächst an einem großen und vielfältigen Datensatz vortrainiert. Ziel ist es, ein umfassendes Sprachverständnis und -wissen zu erlernen. Dies ist sehr rechenintensiv. Anschließend werden die Modelle weiter trainiert, um Anweisungen genauer zu befolgen. Dies wird als Instruction Tuning bezeichnet. Schließlich können diese Modelle für bestimmte Aufgaben fein abgestimmt werden (Fine-Tuning), wenn dies erforderlich ist.
Unser Fazit: Es ist hilfreich zu wissen, wie ein LLM funktioniert!
LLMs entwickeln sich schnell weiter. Neue Architekturen und Embeddings werden ständig entwickelt und evaluiert. Das Verständnis ihrer inneren Funktionsweise ist nützlich, denn es hilft bei der Entwicklung von Anwendungen und der Auswahl von LLMs.
Weitere Blog-Beiträge rund um generative KI und große Sprachmodelle:
- Was sind Large Language Models? Und was ist bei der Nutzung von KI-Sprachmodellen zu beachten?
- Open Source Large Language Models und deren Betrieb: Tipps für den Einstieg
- Retrieval Augmented Generation: Chatten mit den eigenen Daten
- Prompt Engineering: wie kommuniziert man am besten mit großen Sprachmodellen?
- Halluzinationen von generativer KI und großen Sprachmodellen (LLMs)
- Large Action Models (LAMs) nutzen neurosymbolische KI – Die nächste Stufe im Hype rund um Generative AI
- KI in der Softwareentwicklung: Zwischen Produktivitätsschub und Vertrauenskrise – neue Erkenntnisse aus Forschung und Praxis
- KI in der Softwarearchitektur: Wie LLMs die Qualitätssicherung automatisieren
Wir unterstützen Sie dabei, Open-Source LLMs auch in Ihrem Unternehmen erfolgreich zu nutzen!
Unser Team Data Science bietet Ihnen Hilfe bei folgenden Themen:
- Modellauswahl
- Modellbetrieb
- Wie integriere ich Open-Source Large Language Models in meine Applikationen?
- Wie kann ich Open-Source Large Language Models nutzen, um Unternehmensdaten besser zugänglich zu machen (z. B. mithilfe von Retrieval Augmented Generation (RAG))?
- Wie kann ich Open-Source LLMs für meine speziellen Use Cases bzw. Daten feinabstimmen (Finetuning, z. B. mit LoRA)?
- Wie kann ich Open-Source Large Language Models für deutschsprachige Anwendungen oder Code und Software Engineering einsetzen?
- Wie kann ich Large Language Models für meinen Use Case evaluieren?
Unser Lösungsangebot als PDF zum Mitnehmen:
Large Language Models Webinare
Wie kann ich mehr über LLMs lernen?
Das Team Data Science bietet zum Thema LLM Webinare an, darunter sowohl kostenfreie als auch kostenpflichtige Optionen.
Mehr zur Webinarreihe »Zuverlässiger Einsatz von Large Language Models (LLMs)«
1: Open Source LLMs selbst betreiben
2: Retrieval Augmented Generation (RAG)
3: Prompting Essentials – LLMs effektiv nutzen
Sie haben Interesse an einem Seminar für Ihr Unternehmen?
Auf Wunsch bieten wir individuell gestaltete Seminare (auf Deutsch und Englisch) für Ihr Unternehmen an, in denen die Schulungsinhalte gezielt auf Ihre Bedürfnisse abgestimmt werden können.