
In einer Welt, in der Technologie immer weiter voranschreitet, sind sprachgesteuerte Assistenten zu einem nicht mehr wegzudenkenden Teil unseres Alltags geworden. Von IBM Watson und Aleph Alpha Luminous über Apple Siri und Amazon Alexa bis hin zu Google Assistant und Microsoft Cortana sind diese intelligenten Helfer durch maschinelle Spracherkennung in der Lage, unsere Fragen zu beantworten, Aufgaben zu erledigen, Texte vorzulesen und sogar mit uns zu kommunizieren. Einige Nutzer sind jedoch abgeneigt, ihre persönlichen Daten an die Hersteller weiterzugeben. Allerdings ist es mithilfe von neuen, leistungsfähigen Sprachmodellen möglich, mit geringem Aufwand eigene Voice Bots von hoher Qualität zu erstellen, zu individualisieren und natürlich selbst zu betreiben. Dadurch verlassen die Daten nie den Betrieb.
Spracherkennung mit dem LLM Voice Bot
In diesem Blogbeitrag möchten wir Ihnen den LLM Voice Bot vorstellen. LLM steht für »Large Language Model«, und der Voice Bot ist ein Projekt des Fraunhofer IESE, das mehrere bestehende Open-Source-Modelle miteinander kombiniert, um ein eindrucksvolles Spracherlebnis zu erzeugen. Der Aufbau ist modular, sodass einzelne Modelle beliebig ausgetauscht werden können. Dadurch ist es möglich, auch immer wieder neuere und bessere Modelle zu integrieren. Die folgende Architekturübersicht gibt einen Überblick über den Aufbau.
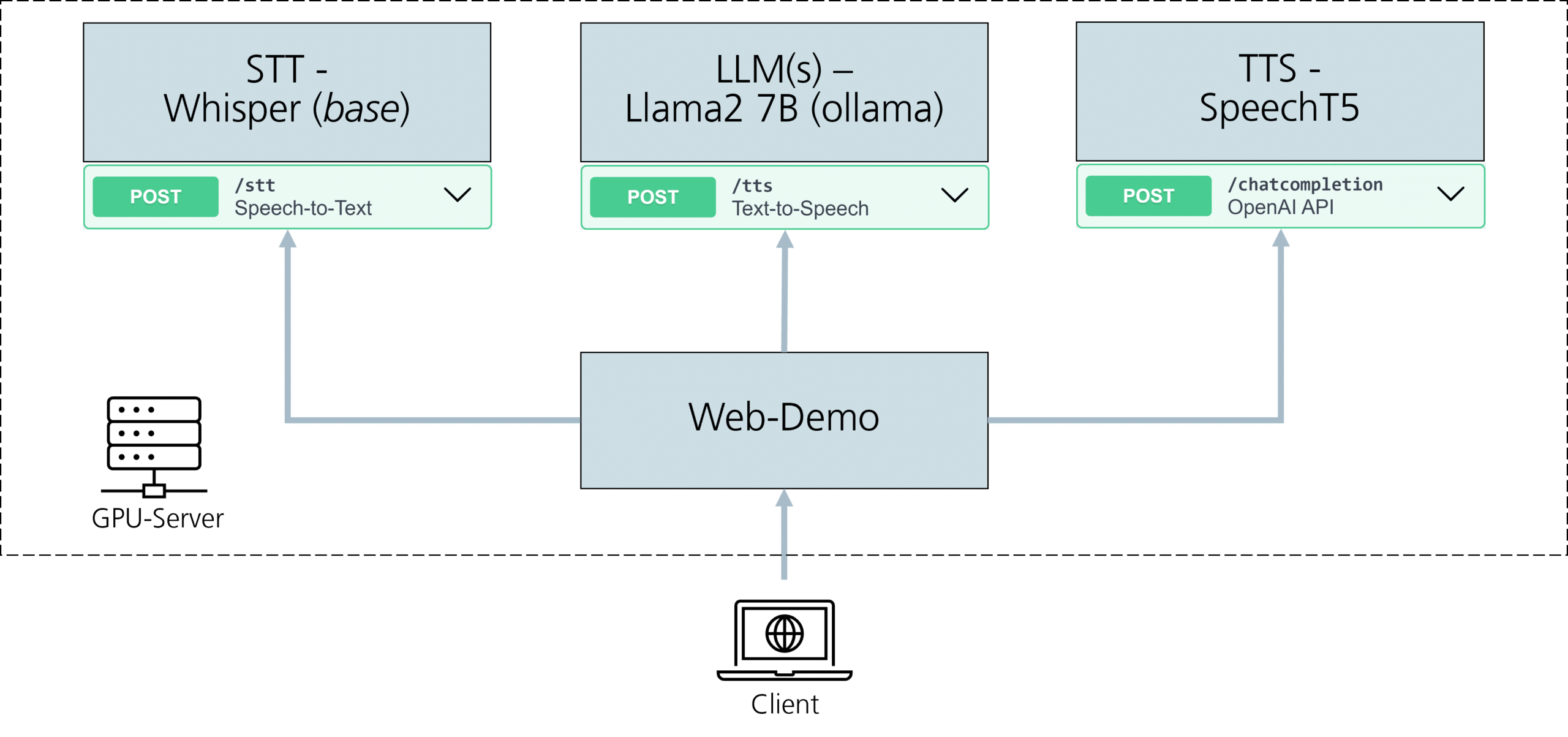
Modelle für Spracherkennung
Im Folgenden stellen wir die Modelle, die wir momentan einsetzen, beispielhaft vor. Die Modelle lassen sich in der Regel bereits mit günstiger Consumer-Hardware betreiben. Um die größten Versionen der Sprachmodelle zu hosten oder um besonders niedrige Latenzen zu erreichen, setzen wir auch spezialisierte Hardware ein, die speziell für KI-Anwendungen entwickelt wurde.
- Spracherkennung mit OpenAI Whisper STT: Der LLM Voice Bot verwendet das Whisper STT-Modell von OpenAI, um gesprochene Sprache in Text umzuwandeln. Dieses Modell basiert auf modernster Spracherkennungstechnologie. Es ermöglicht dem Voice Bot, Ihre gesprochenen Befehle und Fragen präzise zu verstehen und in Text zu übertragen.
- Sprachverständnis mit Meta Llama 2: Ein weiteres entscheidendes Element des LLM Voice Bots ist das Llama 2-Sprachmodell. Es wurde von Meta veröffentlicht. Dieses Modell wird eingesetzt, um den Texteingaben einen Sinn zu geben und die Absichten und Bedeutungen hinter den Fragen und Anfragen zu verstehen. Es ermöglicht dem Voice Bot, kontextbezogene und relevante Antworten in Form von Text zu generieren.
- Natürliche Sprachausgabe mit Microsoft SpeechT5 TTS: Um eine menschenähnliche Sprachausgabe zu erreichen, nutzt der LLM Voice Bot das Microsoft SpeechT5 TTS-Modell. Dieses Modell ermöglicht hochwertige Sprachsynthese, wodurch der Voice Bot in natürlicher und angenehmer Weise antworten kann.
Benutzerfreundliche Weboberfläche für den LLM Voice Bot
Um das interaktive Erlebnis mit dem LLM Voice Bot zu ermöglichen, haben wir eine benutzerfreundliche Weboberfläche entwickelt. Diese Oberfläche zeigt den Chatverlauf an und ermöglicht es dem Nutzer, Fehler in den Textfeldern zu korrigieren. So wird sichergestellt, dass der Voice Bot den Nutzer bestmöglich verstehen kann. Außerdem kann der Nutzer mit dem Modell chatten, ohne zu sprechen, wenn z.B. zu viele Umgebungsgeräusche ein Gespräch verhindern. Die Antwort des Voice Bots kann der Nutzer beliebig wiederholen und in beliebiger Geschwindigkeit anhören.
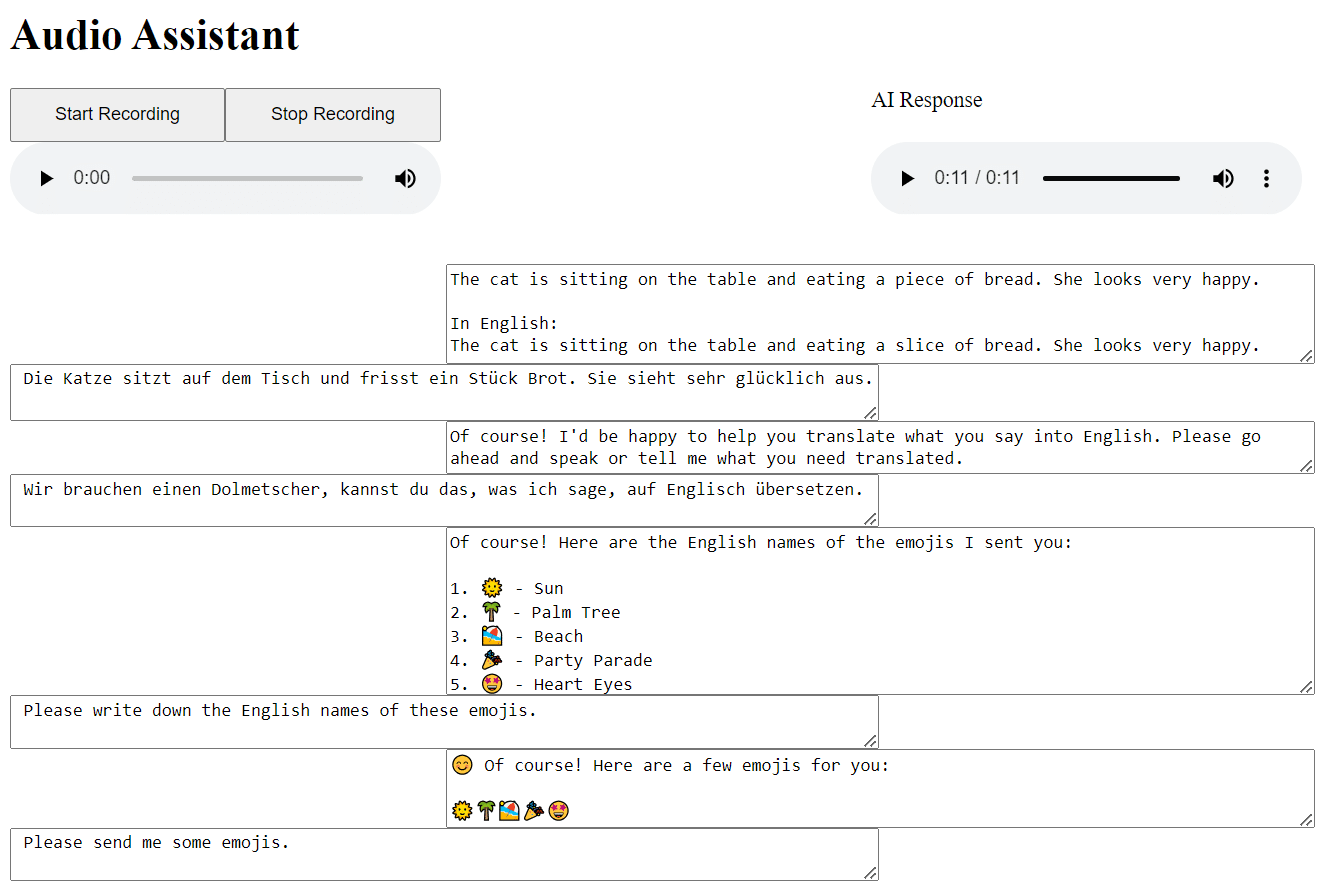
Vielfältige Anwendungsmöglichkeiten für Spracherkennung
Die Einsatzmöglichkeiten für Voice Bots sind vielfältig und flexibel. Sie können als persönliche Assistenten dienen, die Ihnen bei der Organisation Ihres Tages helfen, Informationen liefern und sogar einfache Aufgaben erledigen. Deshalb haben Voice Bots das Potenzial, unser tägliches Leben zu verbessern und uns effizienter zu machen.
Anwendungsfall Automatische Übersetzung mit Spracherkennung
Für neuere Sprachmodelle ist es eine einfache Aufgabe, Sprache sinngemäß zu übersetzen. Tatsächlich sind sogar alle drei der von uns verwendeten Modelle von sich aus in der Lage, natürliche Sprache zu übersetzen. Am einfachsten ist es dabei, dem Sprachmodell direkt die Anweisung zu geben, als Dolmetscher zu agieren. Dabei muss der Voice Bot nicht einmal konfiguriert werden, um die Aufgabe zu erledigen.
Fazit: Sind Sprachassistenten die Zukunft?
Der LLM Voice Bot ist ein spannendes Beispiel für die Zukunft der sprachgesteuerten Assistenten. Mit fortschrittlichen Modellen für Spracherkennung, Sprachverständnis und Sprachausgabe bietet er ein eindrucksvolles und menschenähnliches Spracherlebnis. Die vielfältigen Anwendungsmöglichkeiten machen ihn zu einem wertvollen Werkzeug in unserem technologiegetriebenen Alltag, ohne die Datensouveränität der Nutzer zu beeinträchtigen. Bleiben Sie also gespannt auf weitere Entwicklungen in diesem aufregenden Bereich! Wenn Sie sich für das Thema interessieren oder darüber nachdenken, Voice Bots selbst einzusetzen, treten Sie gerne mit uns in Kontakt.
Zum Weiterlesen:
Referenzen:
- Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2023, July). Robust speech recognition via large-scale weak supervision. In International Conference on Machine Learning (pp. 28492-28518). PMLR.
- Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., … & Scialom, T. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Ao, J., Wang, R., Zhou, L., Wang, C., Ren, S., Wu, Y., … & Wei, F. (2021). Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing. arXiv preprint arXiv:2110.07205.