
Nutzerinnen und Nutzer der beliebten Musik-Streaming-Plattform »Spotify« kennen den persönlichen »Mix der Woche« oder die täglichen Empfehlungen. Doch was wäre, wenn wir die Logik hinter diesen passgenauen Empfehlungen nutzen könnten, um die Konzepte hinter komplexen Systemen abzusichern? Wie lässt sich etwa der Erfolg eines digitalen Marktplatzes vorhersagen, bevor die erste Zeile Code geschrieben ist? Die Antwort liegt in den Mechanismen, die Spotify für seine Empfehlungen nutzt. In diesem Beitrag schauen wir hinter die Kulissen der Spotify-Algorithmen und zeigen, wie wir diesen Ansatz zur Simulation von Software-Systemen nutzen. Indem wir das Prinzip der »Vektor-Ähnlichkeit« auf Angebot und Nachfrage übertragen, schaffen wir eine realistische Entscheidungsgrundlage für Ihr nächstes Projekt – von der Bedarfsanalyse bis zur dynamischen Marktsimulation.
Wie funktioniert Match-Making in digitalen Systemen?
Algorithmen sind das unsichtbare Herz von Spotify. Sie erstellen nicht nur personalisierte Playlists, die scheinbar genau zu unserem Musikgeschmack passen, sondern organisieren im Hintergrund ein komplexes System des Zuordnens, Vergleichens und Gewichtens von Daten. Was dabei oft übersehen wird: Solche Mechanismen beschränken sich keineswegs auf Musikplattformen. Viele digitale Dienste – von Online-Shops bis zu Streaming-Portalen – basieren auf ähnlichen Matching-Prinzipien, um Nutzerinnen und Nutzer mit Inhalten, Produkten oder Dienstleistungen zueinander in Beziehung zu setzen.
Gerade deshalb ist Spotify mehr als nur ein Musikdienst: Die Plattform kann auch als anschauliches Beispiel dafür dienen, wie softwarebasierte Systeme Verhalten modellieren, Präferenzen abbilden und daraus Entscheidungen ableiten. In diesem Beitrag betrachten wir Spotifys Ansatz nicht technisch, sondern konzeptionell – und nutzen ihn als Inspiration dafür, wie sich Matching- bzw. Empfehlungssysteme auch auf die Simulation von Software-Systemen übertragen lassen.
Wie berechnet Spotify den Musikgeschmack mit Algorithmen?
Individuelle, und vor allem passende Empfehlungen setzen voraus, dass der persönliche Geschmack möglichst genau bekannt ist. Das gilt selbstverständlich auch für den Musikgeschmack. Spotify muss diesen für jede Hörerin und jeden Hörer auf der Plattform bestimmen und abbilden können, sodass automatisiert Vorschläge berechnet werden. Wie aber misst Spotify den Geschmack der Nutzerinnen und Nutzer?
Spotify kennt den Geschmack durch Wissen darüber, welche Musikstücke bereits abgespielt wurden. Da jedoch niemand dasselbe Musikstück wieder und wieder vorgeschlagen bekommen möchte, dürfen Vorschläge nicht identisch, sondern müssen ähnlich sein. Das bedeutet, dass Spotify Musikstücke vergleichbar machen muss. Wie aber vergleicht man Musikstücke?
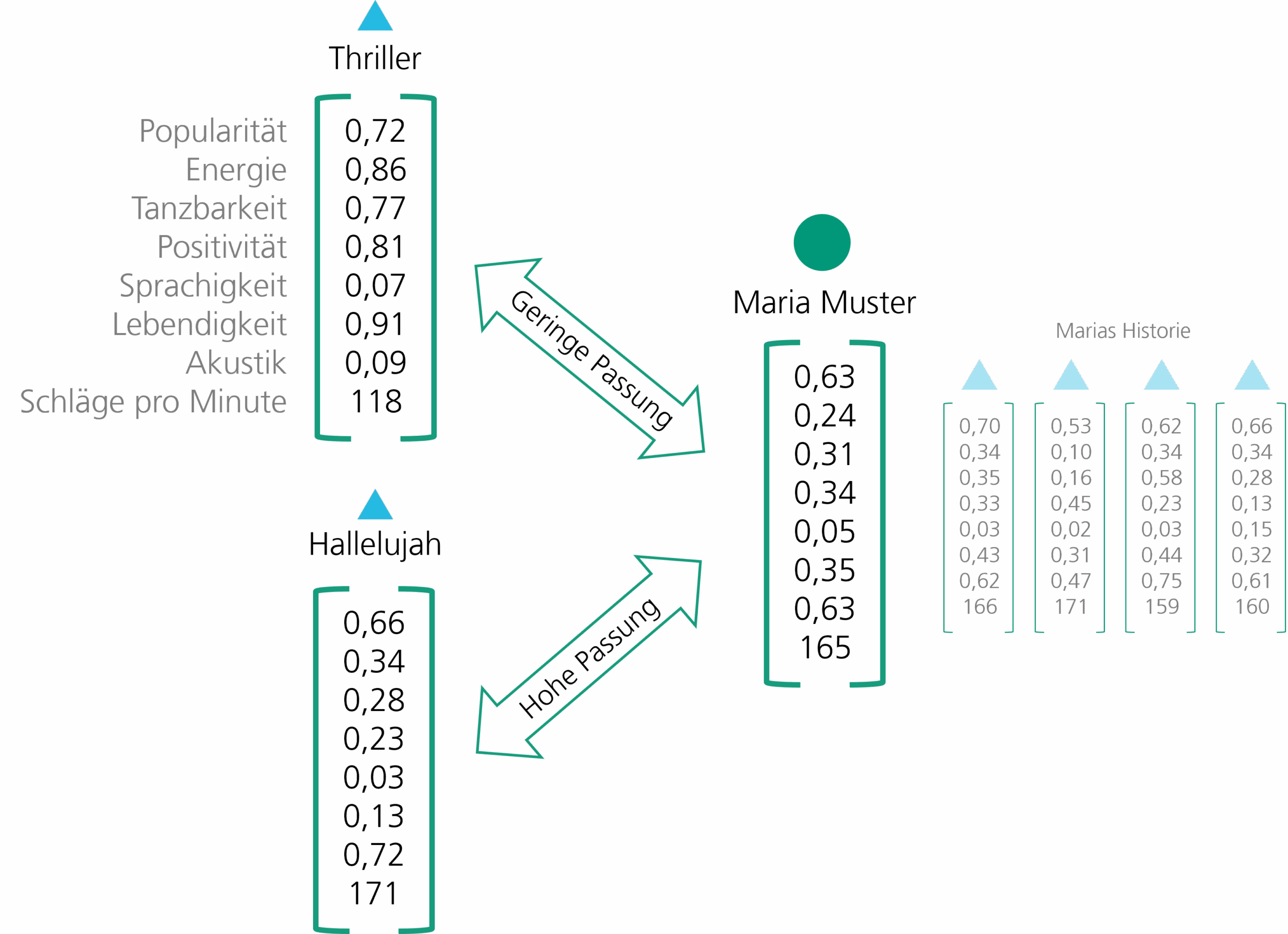
Spotify erreicht dies, durch die Charakterisierung der Musikstücke in Merkmalsprofilen und der Gegenüberstellung der modellierten Geschmacksprofile der Nutzenden (»Taste Profile«). Empfehlungen werden aus dem Grad ihrer Übereinstimmung abgeleitet. Teil der Charakterisierung sind etwa Lautstärke, Lebendigkeit oder Tanzbarkeit. Jedes Lied kann auf einer Skala mit Werten zwischen 0 und 1 für jede Eigenschaft beschrieben werden. Eignet sich ein Lied gut zum Tanzen, wird dies durch einen hohen Wert der »Tanzbarkeit« repräsentiert. Weiterhin zeichnet sich jedes Lied durch zusätzliche, nicht normierte Metadaten wie die Länge des Stücks oder die Schläge pro Minute (BPM) aus. Überdies verwendet Spotify plattformspezifische, nutzungsbasierte Metadaten. Diese beschreiben nicht nur die Eigenschaften der Musik selbst, sondern auch, wie, wann und in welchem Kontext sie gehört wird. Sie entstehen aus dem tatsächlichen Nutzungsverhalten, etwa aus Interaktionssignalen wie Anspieldauer oder Skip-Verhalten, sowie aus Geräte- und Situationsdaten wie Standort oder Bewegungsaktivität. Auf diese Weise kann Spotify erfassen, zu welchen Tageszeiten, an welchen Orten oder in welchen Nutzungssituationen bestimmte Musik typischerweise gehört wird, etwa unterwegs, beim Sport oder in Ruhephasen [1].
Kosinus-Ähnlichkeit und Vektoren: Die Mathematik hinter dem User-Profil
Ein Musikstück vorzuschlagen, das den bisher gespielten Musikstücken ähnelt, heißt folglich, ein Musikstück zu finden, das eine ähnliche Werteverteilung aufweist. Für Nutzende mit typischerweise hohem Bedarf an Tanzbarkeit werden dies andere Stücke sein als für solche, die vornehmlich Musik mit hohem Akustikanteil bevorzugen. Damit Spotify diese ähnlichen Musiktitel effizient berechnen kann, repräsentiert es Musikstücke als Vektoren, deren Komponenten die Charakteristiken der Stücke abbilden [2].
Das bedeutet, für sämtliche Musikstücke hat Spotify mittels entsprechender algorithmischer Analysen eine Instanz eines Vektors gebildet, der zu allen Eigenschaften einen konkreten Wert vergibt. Michael Jacksons »Thriller« weist laut Musicstax eine Tanzbarkeit von 0,77 auf [3] wohingegen »Hallelujah« von Leonard Cohen eine eher geringe Tanzbarkeit von 0,28 zeigt [4].
Da sich musikalischer Geschmack eines Menschen nicht direkt messen lässt, wertet Spotify Nutzungsdaten aus. Auf Basis der individuellen Hörhistorie und im Vergleich mit ähnlichen Nutzergruppen, etwa gemäß Wohnort oder Alterskohorte, wird das Geschmacksprofil gebildet. Mit zunehmender Nutzungsdauer wird dieses Profil kontinuierlich verfeinert und präzisiert.
Mit Instanzen von Vektoren für Musikstücke und Hörerinnen bzw. Hörer kann nun berechnet werden, welche Lieder zu einem Geschmack passen, wie in Abbildung 1 exemplarisch dargestellt. Anders ausgedrückt: Spotify kann durch geschicktes Vergleichen, z.B. anhand der Kosinus-Ähnlichkeit zwischen Vektoren, die persönlichen Playlists mit Empfehlungen befüllen. Hierfür nutzt es eigens entwickelte Algorithmen, die mit den riesigen Datenmengen der Streaming-Plattform funktionieren [5].
Vom Empfehlungs-Algorithmus zur Software-Simulation
Die ausgesprochenen Empfehlungen zu Musikstücken, die einer Hörerin oder einem Hörer gefallen, sind eine Vorhersage einer Passung zwischen einem Angebot und einer Nachfrage. Das ist eine Aufgabenstellung, der nicht nur Spotify gegenübersteht. Marktplätze wie Amazon schlagen passende Produkte vor, Dating-Apps wie Tinder suchen die passenden Partnerinnen und Partner, und YouTube empfiehlt vermeintlich interessante Videos. Alle versuchen, bestmöglich die Ähnlichkeit zwischen Angebot und Nachfrage zu berechnen, um das wahrscheinlichste »Match« vorherzusagen und der Nutzerschaft nahezulegen. Abbildung 2 zeigt die Struktur anhand des Beispiels von Spotify.

Die Idee der Empfehlungen auf Basis eines Vergleichs zwischen Angebot und Nachfrage ist folglich über Branchen hinweg anwendbar. Doch bevor ein Betreiber dieses Instrument nutzen kann, steht er vor anderen Herausforderungen: Er muss ein Konzept für eine Software und insbesondere ein Geschäftsmodell entwerfen, das langfristig tragfähig ist. Das ist es nur dann, wenn die Plattform eine ausreichende Anzahl »Matches« vermittelt. Das wiederum geschieht nur, wenn Angebot und Nachfrage in ausreichendem Umfang auf der Plattform vertreten sind.
Was genau bedeutet das jedoch konkret? Welche Angebote und welche Konsumenten führen zu welchen Transaktionen auf der Plattform, und damit zu welchen möglichen Einnahmen? Hierfür ist eine Vorhersage notwendig – und das sollte uns bekannt vorkommen: Was Spotify für seine Empfehlungen nutzt, verwenden wir für die Simulation eines Software-Systems und seiner Interaktionen.
Geschäftsmodelle mit realitätsnahen Simulationen absichern
Die Zutaten für eine Simulation eines Software-Systems mit Austauschen zwischen Anbietern und Nachfragern auf einer gemeinsamen Plattform kennen wir bereits:
- Wir benötigen die Charakterisierung der Angebote und ihrer Anbieter sowie der Nachfragenden, das heißt die Eigenschaften, anhand derer ein Angebot und sein Anbieter beschrieben werden können, und anhand derer ein Nachfragender entscheidet, ob er ein Angebot nutzt.
- Wir benötigen eine realistische Verteilung der Werte für die einzelnen Eigenschaften der Angebote und Nachfragenden, die dem entspricht, was auf dem Markt angeboten und nachgefragt wird.
- Wir benötigen die Abbildung der Angebote und Nachfragenden in Form von Vektoren, um die Berechnung von Ähnlichkeit vornehmen zu können.
Jede Simulation kann jedoch nur so gut sein wie die Daten, auf denen sie basiert. Am einfachsten ist das, wenn ein System bereits viele Nutzende hat, deren Daten direkt in Vektoren übersetzt werden können. In der Realität stellt sich die Frage der Tragfähigkeit einer Idee jedoch gerade zu Beginn eines Projekts. Folglich soll das Treffen von Vorhersagen mittels Simulation auch ohne bestehende Nutzerschaft möglich sein. Daher müssen andere Wege genutzt werden, um die nötigen Daten zu gewinnen:
- Bedarfsanalysen dienen dazu, Anforderungen der relevanten Stakeholdergruppen systematisch zu erfassen.
- Markt- und Domänenanalysen schaffen das Verständnis über fachliche Zusammenhänge und typisches Verhalten von Akteuren im Markt – neben den anvisierten Zielgruppen der Plattform auch von Konkurrenten und komplementären Anbietern.
Auf dieser Basis lassen sich Abschätzungen zur Anzahl der Angebote und Anbieter, zum Verhalten der Akteure sowie zu möglichen Einflussfaktoren vornehmen. Diese fließen in die Erzeugung von Vektoren ein, anhand derer die Simulation erfolgt. Diese liefert wertvolle Erkenntnisse über die Tragfähigkeit eines Geschäftsmodells als Grundlage für Entscheidungen zum Design eines komplexen Software-Systems. Sie geht dabei über die statischen Betrachtungen eines Entwurfs von Geschäftsideen wie mittels »Tangible Ecosystem Design« hinaus, indem sie dynamische Zusammenhänge berücksichtigt [6].
KI-Agenten und dynamische Modelle: Die Zukunft der System-Simulation
Um eine realitätsnahe, dynamische Simulation eines Software-Systems und des Verhaltens von Akteuren zu ermöglichen, verstehen wir die Vektoren nicht als einmal festgelegte Zahlenreihen, sondern verändern sie dynamisch. Einerseits verändern sie sich durch simulierte Aktivitäten auf der Plattform selbst, also Angebot und Nachfrage verändern sich mit jeder erfolgten Transaktion. Andererseits treffen auch in der echten Welt nicht alle Menschen und Organisationen rein auf Zahlenbasis optimale und vorherbestimmbare Entscheidungen. In künftigen Blog-Beiträgen stellen wir detaillierter vor, wie wir eine Dynamik analog zur realen Welt abbilden, indem wir die simulierten Akteure in Form autonomer KI-Agenten selbstständige Entscheidungen treffen lassen – im Rahmen definierter Grenzen.
Simulieren Sie Ihr System!
Haben Sie Interesse am Aufbau einer KI-gestützten Simulationsumgebung für Ihr Software-System? Wir unterstützen Sie gerne bei der Validierung Ihrer Geschäftsmodellidee für Ihr bestehendes oder zukünftiges digitales Ökosystem oder Software-System.
Referenzen
[1] Die Vermessung der Popmusik: Woher die Algorithmen von Spotify wissen, was wir zum Einschlafen hören wollen | BR.de. [Online] (accessed: Jan. 26 2026).
[2] Spotify, „Audio Features,“ [Online].
[3] Tonart, BPM & Auswertung von Thriller von Michael Jackson | Musicstax. [Online] (accessed: Jan. 9 2026).
[4] Tonart, BPM & Auswertung von Hallelujah von Leonard Cohen | Musicstax. [Online] (accessed: Jan. 13 2026).
[5] GitHub, GitHub – spotify/annoy: Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk. [Online] (accessed: Jan. 9 2026).
[6] Fraunhofer-Institut für Experimentelles Software Engineering IESE, Fraunhofer IESE Tangible Ecosystem Design [Online] (accessed: Jan. 26 2026).