
Krankenhauskeime sind eine unsichtbare, aber tödliche Gefahr und ein großes Problem in unserem Gesundheitssystem. Schätzungen zufolge sterben allein in Deutschland jedes Jahr 10.000 bis 20.000 Menschen, weil sie sich im Krankenhaus mit Krankheitserregern infizieren, sog. nosokomiale Infektionen [1]. Besonders gefährlich sind hierbei Infektionen mit multiresistenten Keimen, also solche, gegen die Antibiotika nur schwer anschlagen bzw. man auf Reserveantibiotika zurückgreifen muss. Die herkömmlichen Methoden, um die Ausbreitung solcher Krankenhauskeime zu kontrollieren, sind oft teuer und ineffizient. Doch was wäre, wenn künstliche Intelligenz (KI) uns dabei helfen könnte? Genau das haben wir im Fraunhofer-Projekt Respivir untersucht: In einem virtuellen Krankenhaus wurde das Infektionsgeschehen simuliert, um zu testen, wie gut KI-Modelle die Infektionsketten vorhersagen können.
Datenbasierte Modelle können bei der Modellierung der Ausbreitung von Infektionen unterstützen. Dies ermöglicht nicht nur, retrospektiv Problembereiche wie Schwächen in der Hygiene zu identifizieren, sondern auch, eine effiziente Teststrategie zu entwickeln, die die weitere Ausbreitung möglichst effektiv verhindert. So kann schon bei der Feststellung einer oder weniger Infektionen schneller entschieden werden, welche Personen oder Personengruppen getestet werden müssen, da sie ein erhöhtes Risiko aufweisen, sich mit dem Keim infiziert zu haben. Im Projekt Respivir [2] haben wir zur Untersuchung dieses Anwendungsfalls ein Krankenhaus nachmodelliert und die Übertragung eines häufigen Erregers (Clostridioides difficile) von nosokomialen Infektionen, welcher aufwändige Hygienemaßnahmen erfordert [5], in diesem simuliert. Hierbei haben wir synthetisch Daten erzeugt, wie sie auch typischerweise in realen Krankenhausinformationssystemen (KIS) und Dokumentationssystemen vorliegen.
Wir konnten zeigen, dass sich auf Basis dieser Daten Patientenpfade rekonstruieren und transparente KI-Modelle erstellen lassen. Die Analysen der modellbasierten Prognosen zeigten, dass diese als Decision Support System Teststrategien ermöglichten, die nichtdatengestützte Teststrategien in ihrer Effektivität deutlich übertreffen, aber in ihrer Fehlerrate von der Auflösung und Qualität der erfassten Daten abhängen. So wirken sich Fehler bei der Datenerfassung, insbesondere während der Modellanwendung negativ auf die Güte der Prognosen aus.
Wie wir die Ausbreitung von Krankenhauskeimen mit KI simulieren
Ganze Kohorten von Patientinnen und Patienten [3] zu testen ist zeit- und ressourcenaufwendig. Wenn die Infektionsrate sehr niedrig oder eine Infektion weitgehend ungefährlich ist, lohnt es sich kaum, viele Tests durchzuführen, und der Mehrwert in der Patientenversorgung ist gering. Wir haben uns daher mit Methoden aus dem Bereich Data Science und Künstliche Intelligenz dem Problem angenähert. Das Ziel unseres Prognosemodells war hierbei die individuelle Infektionswahrscheinlichkeit für alle übrigen Patienten abzuschätzen, sobald ein positives Testergebnis für einen bestimmten Patienten im Krankenhaus vorliegt. Dadurch kann eine KI-basierte Teststrategie Patienten mit höheren Infektionswahrscheinlichkeiten priorisieren.
Grundsätzlich haben Kliniken in Deutschland verschiedene Datenquellen zur Verfügung, die für ein solches Prognosemodell infrage kommen. Hierzu zählen vornehmlich Dokumentations- und Krankenhausinformationssysteme (KIS). Es stellt sich allerdings die Frage, ob die Informationen über Patientenpfade, die sich aus Daten rekonstruieren lassen, wie sie typischerweise in solchen Systemen vorliegen, hinreichend sind, um geeignete KI-Modelle zu erstellen. Mit anderen Worten: mit welcher Genauigkeit kann mittels KI-Methoden vorhergesagt werden, welche Patienten infiziert sind?
Es hat sich herausgestellt, dass bei der Beantwortung dieser Frage der Datenschutz eine Herausforderung ist. Gerade Gesundheitsdaten sind sehr sensibel, deshalb hat man in den allermeisten Fällen nicht ohne explizite Einwilligung der Betroffenen Zugriff auf vorhandene Daten, welche zuvor zu anderen Zwecken erhoben wurden. Auch der Nachweis einer hinreichenden Anonymisierung, die eine Verwendung ermöglichen würde, ist gerade bei Patientenpfaden extrem herausfordernd. Deshalb haben wir uns dazu entschieden die benötigten Daten für eine erste Erprobung synthetisch zu generieren. Wir haben hierzu ein mittleres Krankenhaus mit 11 Normalstationen, einer Intensiv- und einer Notaufnahmestation sowie OPs und Funktionseinheiten wie Radiologie und Endoskopie anhand öffentlich verfügbarer Daten nachmodelliert. Auf dieses Krankenhaus haben wir eine erweiterte Version des Simulationsframework H-outbreak [4] angewendet, welches die Infektionsausbreitung des Erregers Clostridioides difficile in einer Krankenhausumgebung simuliert.
Die Grenzen einer solchen Simulation sind, dass man die Realität nur vereinfacht abbilden kann. Nicht alle Aspekte des Klinikalltags können genau modelliert werden. Wir haben uns für ein einfaches Szenario entschieden, da unser Fokus auf der Vorhersagegüte von KI-Modellen und dem Einfluss der Datenqualität auf diese liegt. So haben wir, beispielsweise die Bewegungen bzw. Lokalisationsänderungen des Klinikpersonals, die ebenfalls als mögliche Übertragungsquelle in Frage kämen, wie auch die Auswirkungen von Vor- oder Begleiterkrankungen auf das Infektionsgeschehen nicht berücksichtigt. Trotz des vereinfachten Szenarios können wir dennoch zumindest vorläufige Rückschlüsse ziehen, denn die synthetischen Daten helfen, unterschiedliche KI-Modelle zu trainieren und diese hinsichtlich ihrer Vorhersagegüte zu beurteilen.

Herausforderungen bei Simulationen von Patienten für ein Prognosemodell
Anhand der generierten Daten haben wir eine Reihe grundlegender Fragen, die sich im Kontext des Einsatzes von KI-Modellen im geschilderten Anwendungsfall stellen, untersucht. Diese umfassten:
- Liefern transparente KI-Modelle, wie Entscheidungsbäume, konkurrenzfähige Vorhersagen im Vergleich zu weniger transparenten KI-Modellen, wie Support Vector Machines (SVM) oder neuronalen Netzen?
- Welchen Einfluss hat die Auflösung der Patientenpfade? Bieten Pfade mit höherer Auflösung, beispielsweise mit Daten über die konkreten Belegungen einzelner Zimmer, mehr Potenzial für bessere Vorhersagen als Pfade, bei denen nur die Station erfasst wird?
- Bieten Teststrategien basierend auf KI-Modellen relevante Vorteile gegenüber »Common Sense« bzw. Baseline-Strategien? Solche Strategien sind etwa die Testung aller Patienten, die sich bisher bekanntermaßen mit dem erkrankten Patienten im gleichen Zimmer (oder der gleichen Funktionseinheit) aufgehalten haben.
- Wie beeinflussen typische Qualitätsdefizite in Daten zu Patientenpfaden die Güte der KI-Prognosen und damit die Effektivität der entsprechenden Teststrategien?
Sind transparente KI-Modelle ähnlich effektiv wie neuronale Netze?
Gerade in sensitiven Bereichen wie dem Gesundheitswesen sind Transparenz und Nachvollziehbarkeit von Entscheidungen wichtige Kriterien. Daher stellt sich die Frage, ob für hinreichend genaue Prognosen komplexe Blackbox-Modelle wie neuronale Netze oder SVM zum Einsatz kommen müssen, oder ob transparente, regelbasierte Modelle wie Entscheidungsbäume ausreichen. Hierzu haben wir fünf typische KI-Modelle für binäre Klassifikationsprobleme parallel angewendet: Neuronales Netz, Random Forest, Naive Bayes, Decision Tree und SVM. Die folgende Grafik zeigt die entsprechenden Ergebnisse für die resultierenden Modelle. Hierbei wird die Güte jedes Modells jeweils mit einer ROC-Kurve (siehe Infobox), also mit der von unten links nach oben rechts verlaufenden Line dargestellt.
Die Receiver Operating Characteristic (ROC)-Kurve eines Klassifikators, in unserem Fall bezüglich der Unterscheidung zwischen ‚infiziert‘ und ‚nicht infiziert‘, erlaubt die visuelle Beurteilung der Güte des Klassifikators entlang unterschiedlicher Entscheidungsgrenzen. Auf der Vertikalen ist hierbei die Sensitivität als Richtig-positiv-Rate aufgetragen. Dies ist der Anteil an Infizierten, der durch das Modell korrekterweise als infiziert vorhergesagt wurde. Auf der Horizontalen ist zur jeweiligen Sensitivität, der Verlust an Spezifität in Form der Falsch-positiv-Rate aufgetragen. Dies ist der Anteil der fälschlicherweise als infiziert klassifizierter Patienten an den nicht infizierten Patienten.
Die Kurve guter Klassifikatoren steigt möglichst steil an und überdeckt dabei eine möglichst große Fläche. Das bedeutet, gute Klassifikatoren erlauben einen großen Anteil der Infizierten zu identifizieren, ohne dass allzu viele Nichtinfizierte fälschlich als Infizierte klassifiziert werden. Dies kann auch konkret über die Area Under Curve (AUC) berechnet werden, die möglichst nahe bei 1 liegen sollte. In den folgenden Abbildungen zeigt die schwarze Diagonale das Ergebnis für den Fall, dass die zu testenden Patienten rein zufällig ausgewählt würden. Dies führt zu einem AUC von 0,5.
Man sieht, dass der Entscheidungsbaum (Decision Tree) vergleichbar gute Vorhersagen trifft wie ein neuronales Netz und deutlich bessere als der SVM-Klassifikator. Da ein Entscheidungsbaum als transparentes Modell leichter nachvollziehbar ist als ein neuronales Netz oder ein Random Forest, werden wir diesen im Folgenden weiterverfolgen.

Mehr Details bei der Datenerfassung sorgen für eine bessere Vorhersage von Krankenhauskeimen
Es stellt sich die Frage, welche Rolle die Auflösung bei der Datenerfassung spielt. Da eine Datenerhebung mit höherem Detailgrad im Allgemeinen zusätzlichen Aufwand verursacht und auch mit Fehlern behaftet sein kann, haben wir den Einfluss unterschiedlicher Auflösungen der Patientenpfade untersucht. Wir haben für den Klassifikator zwei Datensätze mit unterschiedlicher Auflösung (bzw. Detailgrad) aufbereitet. Der erste Datensatz enthält lediglich Informationen über Verlegungen von Patienten zwischen unterschiedlichen Stationen und Aufenthalte in bestimmten Funktionseinheiten wie der Radiologie. Der zweite Datensatz enthält zusätzlich Informationen über Belegungen einzelner Zimmer auf den Stationen und Verlegungen zwischen diesen.
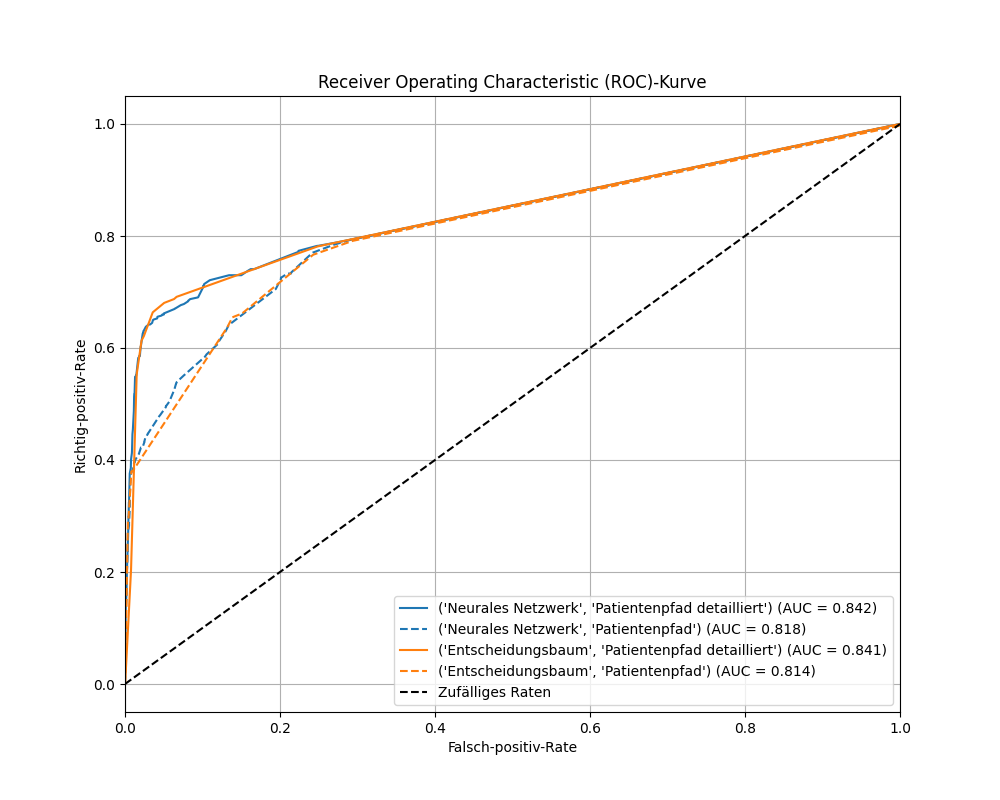
Eine vergleichende Auswertung zeigt, dass die Vorhersagen besser werden, wenn man den Modellen detailliertere Informationen bereitstellt (durchgezogene vs. gestrichelte Linie). Dies war zwar erwartbar aber ad-hoc nicht sicher. Bemerkenswert ist insbesondere, dass dieser Zusammenhang in diesem Fall nicht nur für komplexe Blackbox-Modelle wie neuronale Netze gilt, sondern ebenso für Entscheidungsbäume als einfachere, transparente Modelle.
KI-gesteuerte Teststrategien zeigen Potential im Kampf gegen multiresistente Keime
Eine zentrale Frage bezüglich einer praktischen Anwendung ist, ob der Einsatz von KI überhaupt zu besseren Teststrategien führen kann. Dazu haben wir diese mit »herkömmlichen« Strategien verglichen, welche wir im Folgenden als Baseline-Strategien bezeichnen werden. Zwei naheliegende Baseline-Strategien sind das Testen von allen Patienten, die sich in den vergangenen Tagen mit dem erkrankten Patienten entweder (a) im gleichen Zimmer (respektive der gleichen Funktionseinheit) oder (b) der gleichen Station aufgehalten haben.
In der Grafik unten sieht man, dass die Entscheidungsbaum-basierten Strategien (in Orangegelb) generell bessere Ergebnisse liefern, als die beiden untersuchen Baseline-Strategien (in Blau). Beispielsweise kann man aus der Grafik unten ablesen, dass eine KI-basierte Teststrategie bei einer Falsch-positiv-Rate von nur knapp über 3% schon ein Sensitivität von 66% besitzt, d.h. zwei Drittel aller Infizierten identifizieren würde. Um zwei Drittel aller Infizierten mit der besseren der beiden Baseline-Strategien zu identifizieren, müsste hingegen eine Falsch-positiv-Rate – also einen Anteil an gesunden Patienten, die der Test fälschlicherweise als infiziert einstuft – von ca. 18% akzeptiert werden (blaue gestrichelte Linie). Dies bedeutet gerade bei geringen Prävalenzen, dass bei den Baseline-Strategien deutlich mehr Patienten getestet werden müssen, um einen hinreichend hohen Anteil an Infizierten zu identifizieren, was im Krankenhausalltag häufig nicht praktikabel ist.

Datenqualität ist entscheidend: Müll rein, Müll raus
In einem nächsten Schritt haben wir untersucht, ob bei unsauberen Daten immer noch gute Vorhersagen geliefert werden. Für Datenanalysen und KI-Modelle gilt das bekannte »Garbage In, Garbage Out-Prinzip« (»Müll rein, Müll raus-Prinzip«). Dies besagt, dass bei Datenanalysen die Resultate der Analyse verfälscht werden, wenn die verarbeiteten Daten in einer schlechten Qualität vorliegen. Es stellt sich also die berechtigte Frage, inwieweit typische Qualitätsdefizite den Nutzen solcher Modelle beeinträchtigen können.
In der Praxis tritt bei der Entwicklung und Verwendung von KI-Modellen das Problem auf, dass die Daten häufig nicht perfekt erfasst sind. Die in der Simulation generierten Daten sind aber vollständig und fehlerfrei hinterlegt. Im Klinikalltag sind wiederum viele Szenarien denkbar, bei denen Daten inkorrekt erfasst werden. In einem internen Austausch mit einem Mediziner haben wir folgende erwartbare Defizite identifiziert:
- Die Übermittlung eines Testergebnisses verspätet sich. Es kann sogar unter Umständen dazu kommen, dass eine Probe komplett verloren geht.
- Die Analyseergebnisse werden falsch zugeordnet, heißt, dass die Ergebnisse von Patienten versehentlich miteinander vertauscht werden.
- Die Diagnose wird zu spät dokumentiert. Als Konsequenz kann es bei einer Patientenverlegung dazu kommen, dass ein Raum, der als Übertragungsort infrage kommt, nicht vom System berücksichtigt wird.
- Kurze Aufenthalte für eine spezielle Untersuchung (z.B. in der Endoskopie oder der Radiologie) werden nicht im KIS eingetragen.
- Für einen Patienten wird bei der Aufnahme versehentlich ein falsches Bett ins KIS eingetragen.
Darüber hinaus gibt es noch weitere denkbare Szenarien, die wir aber aufgrund ihrer Vielfältigkeit und Komplexität in unserer Implementierung nicht modelliert haben. Dazu gehört unter anderem ein technischer Mangel bei der Probenentnahme oder -verarbeitung, der zu einem falschen Testergebnis führt. Auch werden sonstige Patientenbewegungen innerhalb des Krankenhauses, sowie eine mögliche Kontaminationsverschleppung durch Personen, die mehrere Bereiche in der Klinik besuchen (wie z.B. private Besucher, Sozialdienst, Seelsorge, Physiotherapie) nicht erfasst.
Wir haben die fünf oben genannten typischen Defizite genauer untersucht und künstlich als Datenqualitätsmängel in die simulierten Daten eingebracht. Wir haben hierbei zwei wichtige Szenarien untersucht:
- Szenario A) Wie wirkt sich die historische Datenqualität auf die Güte des auf diesen Daten trainierten Vorhersagemodells aus?
Dies bezieht sich darauf, dass Modelle, die auf fehlerbehafteten Daten (d.h. mit obigen Qualitätsmängeln) trainiert wurden, anschließend auf (sauberen) Testdaten angewendet werden. - Szenario B) Wie wirkt sich die aktuelle Datenqualität im Rahmen der Modellanwendung auf die Güte der erhaltenen Vorhersagen aus?
Dies bezieht sich darauf, dass das KI-Modell zwar auf sauberen historischen Daten trainiert wurde, aber die Daten in der Anwendung Qualitätsmängel aufweisen.
Um die Auswirkungen beider Szenarien zu untersuchen, haben wir die Trainings-, bzw. Testdaten schrittweise mit einem höheren Anteil an Qualitätsdefiziten augmentiert. Da die Mehrheit der Patientenpfade im Klinikalltag wahrscheinlich korrekt erfasst wird, haben wir für die Eintrittswahrscheinlichkeit der oben genannten Ereignisse einen Bereich von 1-20% betrachtet.
Historische Datenqualität zeigt überraschend geringen Einfluss
In Szenario A) lässt sich für diesen Bereich tatsächlich nur schwer zeigen, dass die Datenqualität die Vorhersagegüte beeinflusst. Weder das AUC-Maß noch der Plot der ROC-Kurve deuten an, dass sich bei einer Verschlechterung der Datenqualität auch die Vorhersagen des KI-Modells verschlechtern. Dies ist bemerkenswert, da man eine Verschlechterung des AUC-Werts erwarten würde. Für den Klinikalltag würde dies für das vereinfachte Szenario bedeuten, dass das KI-Modell eine hinreichend gute Qualität hat, auch wenn es mit unsauberen Daten antrainiert worden ist.
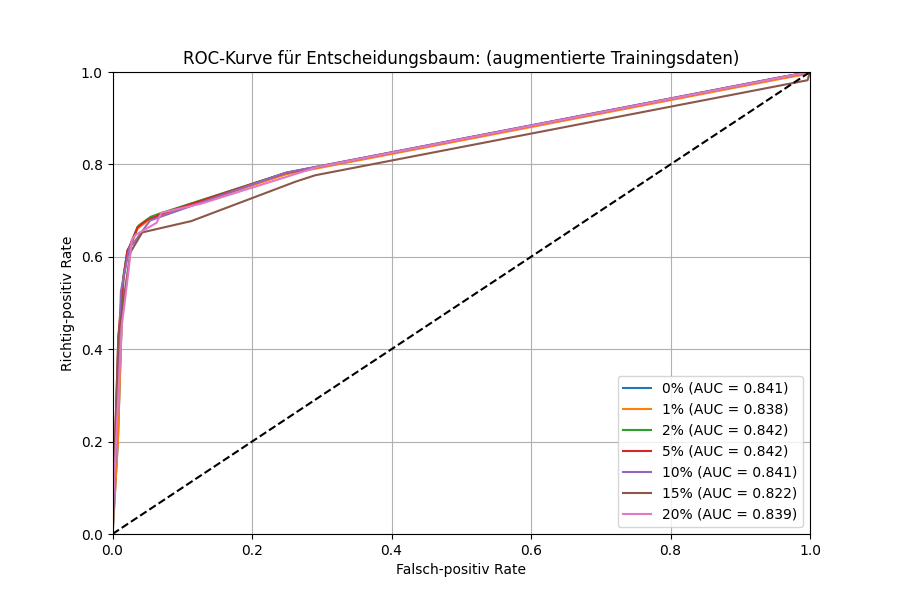
Aktuelle Datenqualität erscheint entscheidend
In Szenario B) sieht der Sachverhalt etwas anders aus. Man sieht klar, dass Qualitätsdefiziten in den aktuell vorliegenden Daten einen relevanten Einfluss auf die Güte der Modellvorhersagen haben. Sowohl die ROC-Kurve als auch der AUC-Wert verschlechtern sich zunehmend bei Verschlechterung der Datenqualität.

Das Potenzial von KI im Kampf gegen Krankenhauskeime
Unsere Simulation war vereinfacht, dennoch konnten erste Rückschlüsse gezogen werden. Wir konnten in unserer Simulationsstudie zeigen, dass bei Qualitätsdefiziten in den Eingabedaten die Güte der Vorhersagen deutlich nachlässt. Vergleichbare Qualitätsdefizite in den Trainingsdaten scheinen hingegen weniger kritisch. Grundsätzlich scheint das Potenzial zu bestehen, auch mit transparenten KI-Modellen Teststrategien zu definieren, die nicht datenbasierten Strategien überlegen sind. Um diese Effekte quantitativ genauer zu fassen, sind allerdings weitere Untersuchungen notwendig. Denkbar ist eine Erweiterung des Simulationsframeworks, um den Klinikalltag realistischer zu modellieren. Als wichtigen Schritt sehen wir allerdings insbesondere die Erprobung auf realen Klinikdaten im Rahmen einer Fallstudie oder Pilotumsetzung.
Ausblick
Unsere Simulation hat gezeigt, welches Potenzial KI bei der Bekämpfung von Krankenhauskeimen haben könnte. Um die Modelle weiter zu verbessern und ihre Praxistauglichkeit zu beweisen, planen wir weitere Forschung. Denkbar sind realistischere Simulationen, aber auch eine Pilotumsetzung mit realen Klinikdaten.
Haben Sie Interesse an einer Zusammenarbeit oder möchten mehr über unsere Forschung erfahren?
Kontaktieren Sie uns gerne!
Quellen
[1] RKI FAQs: Krankenhausinfektionen und Antibiotikaresistenz
[2] Fraunhofer ZDD: Projekt »RespiVir«
[3] Aus Gründen der besseren Lesbarkeit wird in folgendem auf die gleichzeitige Verwendung weiblicher und männlicher Sprachformen verzichtet und das generische Maskulinum verwendet. Sämtliche Personenbezeichnungen gelten gleichermaßen für beide Geschlechter.