
Weak requirements often break sprint plans because unclear user stories lead to rework and long clarification loops. LLM-based review of user stories is a promising approach that helps teams detect quality gaps earlier. Instead of discovering problems like missing acceptance criteria during sprint planning, teams can identify them already during refinement. Typical symptoms include stories that are difficult to estimate, too large for a sprint, or hard to test. As a result, teams spend valuable time clarifying details instead of implementing features.
Artikel in Deutsch lesen: Verbesserung der Qualität von User Stories mit LLMs
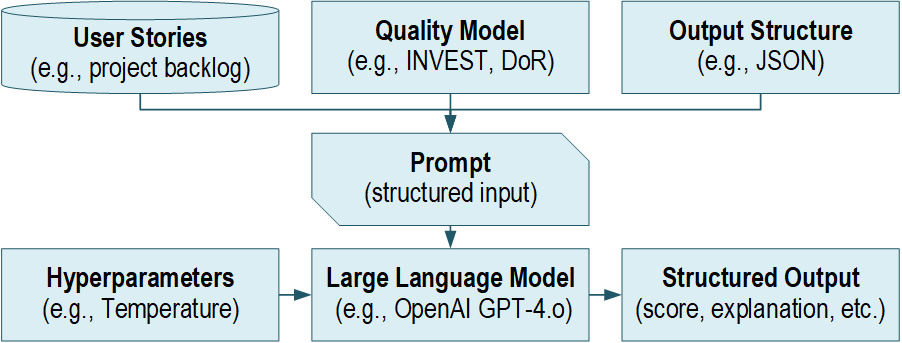
How LLM user story review works
From backlog item to structured feedback
DeepQuali implements an LLM-based user story review process that evaluates backlog items against established quality rules. To ensure consistent results, story content is prepared in a structured format before it is sent to the LLM, and the prompt instructs the model to produce a structured response.
As a result, the output is easier to scan during refinement meetings. Furthermore, teams can compare several stories more easily because findings are grouped by quality rules. Since issues are already linked to specific criteria, teams can transform them into concrete edits more quickly. In addition, this structure helps teams delegate tasks to the right person.
Output of the LLM-based user story review
The output is designed to be actionable and consistent, so it usually includes a score per rule together with a short explanation. In addition, it lists concrete issues linked to each rule, while it also adds an importance level to support prioritization because not every issue blocks implementation. Finally, the system provides improvement suggestions so that teams can move directly from diagnosis to action.
User story readiness in LLM-based user story review
In addition, DeepQuali produces a summary assessment that indicates whether a story appears ready to implement. Consequently, teams receive a quick readiness signal that helps them decide whether a story can move forward into sprint planning.
In the evaluation setting, readiness was linked to several practical signals because teams rely on clear criteria during planning. For example, stories needed clear acceptance criteria and a sufficient description. In addition, they had to follow the team template and include an effort estimate, so the readiness summary aligns with common agile planning practices.
INVEST criteria in user story quality review
INVEST is a widely used guideline for writing high-quality user stories [1]. In the DeepQuali approach, this checklist supports the LLM-based user story review because each letter represents a different quality property.
- Independent
A story should be implementable without relying on unfinished stories. This reduces dependencies and helps avoid waiting during a sprint. - Negotiable
A story should describe the goal rather than a fixed solution so that the team can still discuss different implementation options. - Valuable
The story should provide clear value to users or stakeholders because this makes prioritization easier and focuses development on real benefits. - Estimable
The team must be able to estimate the work. If this is difficult, the story often lacks context or clear scope boundaries. - Small
The story should fit into a sprint. If it is too large, it should be split into smaller units that still deliver value. - Testable
Success must be verifiable, and therefore acceptance criteria and test scenarios should be clearly defined.
Definition of Ready in user story quality review
A Definition of Ready describes the minimum conditions a user story must meet before entering a sprint because teams want to avoid pulling incomplete stories into planning. Many teams therefore extend this checklist beyond the basic story format.
For example, the evaluation used criteria such as acceptance criteria quality, the presence of effort estimates, template completion, prerequisites, and test scenario descriptions. Because these rules reflect local development practices, the LLM-based user story review can evaluate stories according to the team’s own standards.
Consistency and Reliability of LLM-based user story review
Quality assurance requires consistent results, and therefore DeepQuali prioritizes stability over creativity. If an LLM produces different results for the same story, teams quickly lose trust.
For this reason, the approach reduces randomness in the model configuration and enforces structured output. As a result, repeated checks become predictable and easier to interpret.
Using LLM-based user story review in backlog refinement
A practical usage pattern is to treat the LLM output as a checklist rather than a final decision. For example, teams can run a short pre-check before refinement so that they detect missing acceptance criteria or unclear value early.
Afterwards, teams can run a second check before sprint planning because this confirms whether a story is ready for implementation and therefore reduces sprint risks. In practice, it also helps to distinguish between two levels of feedback. First, the tool lists issues and explanations. Afterwards, it suggests possible improvements so that teams remain in control of the final decision.
Evaluation of the LLM user story review approach
Study setup
The evaluation involved two German SMEs and two agile projects from different domains. Experts reviewed a small set of user stories and compared their judgments with the LLM’s assessments.
Because the prototype was not directly integrated into development tools, experts interacted with the system during guided workshops and surveys. Therefore, the results mainly provide early insights into feasibility and practical usefulness.
Agreement was stronger on readiness than on detailed ratings
Experts did not always agree on detailed criterion ratings. However, agreement was stronger for the “Small” criterion, while experts also agreed more often on the overall readiness assessment. As a result, the readiness summary proved easier to align on during discussions.
This observation highlights an important reality of agile development because user story quality can be subjective. Therefore, an LLM can support consistency, but it cannot replace team alignment.
Where the LLM helped most
Experts especially appreciated the explanations provided by the LLM because these explanations made it easier to understand why a story received a certain rating. In addition, they helped teams decide what to improve first.
Furthermore, the readiness summary proved useful because it provides a quick overview of story quality. As a result, teams can decide faster whether a story is ready for implementation. Therefore, short explanations combined with a clear readiness signal may be more helpful than complex scoring schemes.
Where friction appeared
Three practical limitations emerged during the evaluation. First, some checks require backlog context, so missing context can affect the assessment of dependencies. Second, false alarms can reduce trust, and therefore fewer but more precise findings may be preferable. Third, story size expectations vary across organizations, and as a result the interpretation of the “Small” criterion must match local writing practices.
Most important takeaways for practitioners
- Use LLMs to detect missing acceptance criteria and unclear value early.
- Focus on explanations and improvement suggestions rather than scores alone.
- Provide context when possible, especially regarding dependencies.
- Align the quality checklist with your team’s writing conventions.
- Integrate the approach into backlog tools to support daily workflows.
Conclusion: AI as a Compass in Refinement
DeepQuali demonstrates how a LLM can support user story quality assurance when it follows explicit quality rules and produces structured feedback. For agile teams, this approach offers practical benefits because reviews become faster, readiness decisions become clearer, and improvement suggestions become more actionable.
Nevertheless, LLM feedback should be treated as reviewer input rather than final truth because human judgment remains essential. Domain knowledge, project context, and team conventions still shape what makes a user story truly ready for implementation.
References
[1] Wake, B. “INVEST in Good Stories, and SMART Tasks.”

