
Qualitätsschwache Anforderungen bringen Sprintpläne oft ins Wanken, weil unklare User Stories zu Nacharbeit und langwierigen Klärungsschleifen führen. Die LLM-basierte Überprüfung von User Stories ist ein vielversprechender Ansatz, mit dem Teams Qualitätslücken früher erkennen können. Statt Probleme wie fehlende Akzeptanzkriterien erst während der Sprint-Planung zu entdecken, können Teams diese bereits im Refinement identifizieren. Typische Anzeichen sind Stories, die schwer zu schätzen, zu groß für einen Sprint oder schwer zu testen sind. Dadurch verbringen Teams wertvolle Zeit mit der Klärung von Details, anstatt Funktionen umzusetzen. In diesem Beitrag zeigen wir auf, wie Large Language Models diese Lücke schließen. Wir stellen den DeepQuali-Ansatz vor, analysieren die Vorteile einer automatisierten Qualitätsprüfung anhand von INVEST-Kriterien und teilen Praxiserfahrungen zur Zuverlässigkeit und Akzeptanz dieses KI-gestützten Feedbacks.
Im Forschungsprojekt DeepQuali haben wir einen Ansatz zur LLM-basierten Bewertung der Qualität von User Stories entwickelt. Dabei dient ein Large Language Model (LLM) als Unterstützung im Backlog-Refinement, bewertet Stories anhand von Qualitätschecklisten wie INVEST und der Definition of Ready eines Teams und liefert strukturiertes Feedback mit Bewertungen, Erläuterungen, erkannten Problemen und Verbesserungsvorschlägen. In einer ersten Evaluation mit zwei mittelständischen Softwareunternehmen schätzten Expertinnen und Experten insbesondere die klaren Erläuterungen des Ansatzes, weil diese die Qualitätsbewertung verständlicher machten. Darüber hinaus bewerteten sie die kompakte Zusammenfassung zur Umsetzungsreife als hilfreich, da sie die Einschätzung des Reifegrads von Stories beschleunigte. Gleichzeitig zeigten sich auch Grenzen, etwa wenn bei einzelnen Bewertungen relevanter Projektkontext fehlte. So kam es mitunter zu Fehlalarmen.
Wie die LLM-basierte Überprüfung von User Stories funktioniert
Vom Backlog-Eintrag zum strukturierten Feedback
DeepQuali implementiert einen LLM-basierten Überprüfungsprozess für User Stories, der Backlog-Einträge anhand definierter Qualitätsregeln bewertet. Um konsistente Ergebnisse sicherzustellen, werden die Inhalte der Stories vor der Übergabe an das LLM in ein strukturiertes Format überführt, und ein Prompt weist das Modell an, eine strukturierte Antwort zu erzeugen.
Dadurch lässt sich die Ausgabe in Refinement-Meetings leichter überblicken. Außerdem können Teams mehrere Stories einfacher vergleichen, weil die Ergebnisse nach Regeln gruppiert sind. Da Probleme bereits mit konkreten Kriterien verknüpft sind, können Teams sie schneller in gezielte Anpassungen übersetzen. Zusätzlich hilft diese Struktur dabei, Aufgaben an die richtigen Personen zu delegieren.
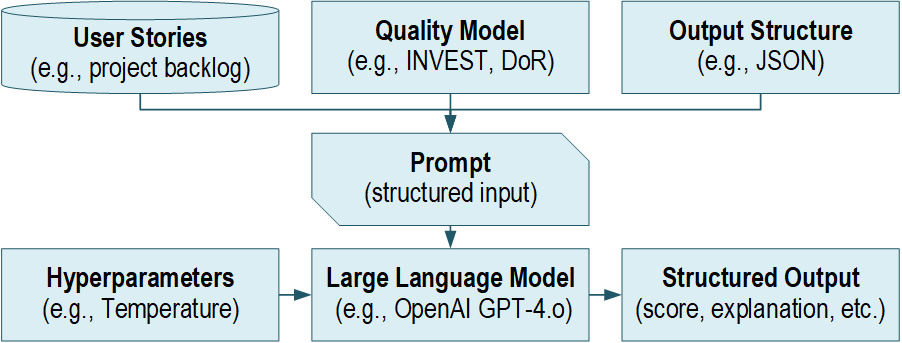
Ausgabe der LLM-basierten Überprüfung von User Stories
Die Ausgabe ist so gestaltet, dass sie handlungsorientiert und konsistent ist. Daher enthält sie in der Regel eine Bewertung pro Regel zusammen mit einer kurzen Erläuterung. Ebenso listet sie konkrete Probleme auf, die den jeweiligen Regeln zugeordnet sind, und ergänzt eine Wichtigkeitsstufe zur Priorisierung, weil nicht jedes Problem die Umsetzung blockiert. Abschließend liefert der Ansatz Verbesserungsvorschläge, sodass Teams direkt von der Diagnose zur Umsetzung übergehen können.
Umsetzungsreife von User Stories in der LLM-basierten Überprüfung
Zusätzlich erstellt DeepQuali eine zusammenfassende Bewertung, die angibt, ob eine Story bereit für die Umsetzung ist. Dadurch erhalten Teams ein schnelles Signal zur Umsetzungsreife, das ihnen hilft zu entscheiden, ob eine Story in die Sprint-Planung aufgenommen werden kann.
Im Evaluationskontext war diese Umsetzungsreife an mehrere praktische Kriterien geknüpft, weil Teams sich in der Planung auf klare Maßstäbe stützen. So mussten Stories beispielsweise klare Akzeptanzkriterien und eine ausreichende Beschreibung enthalten. Darüber hinaus mussten sie der Teamvorlage entsprechen und eine Aufwandsschätzung enthalten, sodass die Zusammenfassung der Umsetzungsreife mit gängigen agilen Planungspraktiken übereinstimmt.
INVEST-Kriterien in der Qualitätsprüfung von User Stories
INVEST ist eine weitverbreitete Leitlinie für das Verfassen qualitativ hochwertiger User Stories [1]. Im DeepQuali-Ansatz unterstützt diese Checkliste die LLM-basierte Überprüfung von User Stories, wobei jeder Buchstabe für eine eigene Qualitätseigenschaft steht.
- Independent
Eine Story sollte umsetzbar sein, ohne von noch nicht abgeschlossenen Stories abhängig zu sein. Dadurch werden Abhängigkeiten reduziert und Teams vermeiden Wartezeiten während eines Sprints. - Negotiable
Eine Story sollte eher das Ziel als eine fest vorgegebene Lösung beschreiben, damit das Team weiterhin verschiedene Umsetzungsoptionen diskutieren kann. - Valuable
Die Story sollte einen klaren Mehrwert für Nutzerinnen und Nutzer oder Stakeholder bieten, weil dies die Priorisierung erleichtert und die Entwicklung auf echten Nutzen fokussiert. - Estimable
Das Team muss in der Lage sein, den Aufwand zu schätzen. Ist das schwierig, fehlt der Story häufig Kontext oder eine klare Abgrenzung des Umfangs. - Small
Die Story sollte in einen Sprint passen. Ist sie zu groß, sollte sie in kleinere Einheiten aufgeteilt werden, die weiterhin Mehrwert liefern. - Testable
Der Erfolg muss überprüfbar sein. Deshalb sollten Akzeptanzkriterien und Testszenarien klar definiert sein.
Definition of Ready in der Qualitätsprüfung von User Stories
Eine »Definition of Ready« beschreibt die Mindestbedingungen, die eine User Story erfüllen muss, bevor sie in einen Sprint aufgenommen wird, weil Teams vermeiden wollen, unvollständige Stories in die Planung zu ziehen. Viele Teams erweitern diese Checkliste daher über das grundlegende Story-Format hinaus.
In der Evaluation wurden etwa Kriterien wie die Qualität der Akzeptanzkriterien, das Vorliegen einer Aufwandsschätzung, die Vollständigkeit der Vorlage, Voraussetzungen und die Beschreibung von Testszenarien herangezogen. Da diese Regeln lokale Entwicklungspraktiken widerspiegeln, kann die LLM-basierte Überprüfung von User Stories Stories nach den eigenen Standards des Teams bewerten.
Zuverlässigkeit der LLM-basierten Qualitätsprüfung von User Stories
Qualitätssicherung erfordert konsistente Ergebnisse. Deshalb priorisiert DeepQuali Stabilität vor Kreativität. Wenn ein LLM für dieselbe Story unterschiedliche Ergebnisse liefert, verlieren Teams schnell das Vertrauen. Daher reduziert der Ansatz die Zufälligkeit in der Modellkonfiguration und erzwingt eine strukturierte Ausgabe. Dadurch werden wiederholte Überprüfungen vorhersehbar und leichter zu interpretieren.
Einsatz der LLM-basierten Überprüfung von User Stories im Backlog-Refinement
Ein praxistaugliches Anwendungsmuster besteht darin, die Ergebnisse des LLM eher als Checkliste denn als endgültige Entscheidung zu betrachten. Teams können etwa vor dem Refinement eine kurze Vorabprüfung durchführen, um fehlende Akzeptanzkriterien oder unklaren Nutzen frühzeitig zu erkennen.
Anschließend können Teams vor der Sprint-Planung eine zweite Überprüfung durchführen, weil diese bestätigt, ob eine Story für die Umsetzung bereit ist, und so Sprint-Risiken reduziert. In der Praxis ist es zudem sinnvoll, zwischen zwei Ebenen des Feedbacks zu unterscheiden. Zunächst listet das Tool Probleme und Erläuterungen auf. Anschließend schlägt es mögliche Verbesserungen vor, sodass Teams die Kontrolle über die endgültige Entscheidung behalten.
Evaluation des LLM-Ansatzes zur Überprüfung von User Stories
Aufbau der Studie
An der Evaluation waren zwei mittelständische deutsche Unternehmen mit zwei agil durchgeführten Projekten aus unterschiedlichen Bereichen beteiligt. Expertinnen und Experten überprüften eine kleine Auswahl von User Stories und verglichen ihre eigenen Einschätzungen mit den Bewertungen des LLM.
Da der Prototyp nicht direkt in Entwicklungstools integriert war, interagierten die Expertinnen und Experten im Rahmen geführter Workshops und Umfragen mit dem Ansatz. Daher liefern die Ergebnisse vor allem erste Erkenntnisse zur praktischen Nutzbarkeit.
Übereinstimmungbei der Umsetzungsreife größer als bei den Detailbewertungen
Die Expertinnen und Experten waren sich bei den detaillierten Kriterienbewertungen nicht immer einig. Die Übereinstimmung war jedoch beim Kriterium »Small« höher, und auch bei der Gesamtbewertung der Umsetzungsreife bestand häufiger Einigkeit. Dadurch erwies sich die Zusammenfassung der Umsetzungsreife in Diskussionen als leichter abstimmbar.
Diese Beobachtung unterstreicht eine wichtige Realität der agilen Entwicklung, weil die Qualität von User Stories subjektiv sein kann. Ein LLM kann die Konsistenz daher unterstützen, die Abstimmung im Team jedoch nicht ersetzen.
Wo der Ansatz am meisten half
Die Expertinnen und Experten schätzten insbesondere die Erläuterungen des Ansatzes, weil diese nachvollziehbar machten, warum eine Story eine bestimmte Bewertung erhielt. Überdies halfen sie den Teams bei der Entscheidung, was zuerst verbessert werden sollte.
Auch die Zusammenfassung der Umsetzungsreife erwies sich als nützlich, weil sie einen schnellen Überblick über die Qualität der Stories bietet. Dadurch können Teams schneller entscheiden, ob eine Story für die Umsetzung bereit ist. Kurze Erläuterungen in Kombination mit einem klaren Hinweis auf die Umsetzungsreife können daher hilfreicher sein als komplexe Bewertungsschemata.
Wo es zu Schwierigkeiten kam
Während der Evaluation zeigten sich drei praktische Einschränkungen. Erstens erfordern einige Prüfungen Backlog-Kontext, sodass fehlender Kontext die Bewertung von Abhängigkeiten beeinträchtigen kann. Zweitens können Fehlalarme das Vertrauen mindern, weshalb weniger, aber präzisere Ergebnisse vorzuziehen sind. Drittens variieren die Erwartungen an die Größe von Stories zwischen Unternehmen, sodass die Interpretation des Kriteriums »Small« den lokalen Schreibgewohnheiten entsprechen muss.
Wichtigste Erkenntnisse für die Praxis
- Verwenden Sie LLMs, um User Stories mit fehlenden Akzeptanzkriterien und unklarem Mehrwert frühzeitig zu erkennen.
- Konzentrieren Sie sich auf Erläuterungen und Verbesserungsvorschläge statt nur auf Bewertungen.
- Stellen Sie nach Möglichkeit Kontextinformationen bereit, insbesondere in Bezug auf Abhängigkeiten.
- Passen Sie die Qualitätscheckliste an die Schreibkonventionen Ihres Teams an.
- Integrieren Sie den Ansatz in Backlog-Tools, um tägliche Arbeitsabläufe zu unterstützen.
Fazit: KI als Kompass im Refinement
DeepQuali zeigt, wie ein LLM die Qualitätssicherung von User Stories unterstützen kann, wenn es expliziten Qualitätsregeln folgt und strukturiertes Feedback liefert. Für agile Teams bietet dieser Ansatz praktische Vorteile, weil Überprüfungen schneller werden, Entscheidungen über die Umsetzungsreife klarer ausfallen und Verbesserungsvorschläge leichter umsetzbar sind.
Dennoch sollte LLM-Feedback als Unterstützung für die menschliche Bewertung verstanden werden und nicht als endgültige Wahrheit, weil menschliches Urteilsvermögen nach wie vor unverzichtbar ist. Domänenwissen, Projektkontext und Teamkonventionen bestimmen weiterhin, wann eine User Story tatsächlich bereit für die Umsetzung ist.
Referenzen
[1] Wake, B. »INVEST in Good Stories, and SMART Tasks.«